AI Agents em 2026: O Stack Completo Para Construir Agentes Que Funcionam de Verdade
Os AI Agents estão em todo lugar, e junto com eles veio um problema clássico: a galera está escolhendo ferramentas antes de entender o que o problema realmente precisa.
Imagina um time que passa três semanas configurando o LangGraph para um chatbot de suporte, com 14 nós em um grafo de estado, um checkpointer customizado gravando no Redis e lógica de retry para chamadas de ferramentas que falham uma vez por semana. No fim das contas, o agente responde perguntas sobre reembolso e chama uma única API. Cinquenta linhas de código usando o SDK da OpenAI com dois servidores MCP teriam resolvido exatamente a mesma coisa. O problema não foi a escolha da ferramenta em si, mas sim não ter mapeado quais camadas o problema realmente precisava antes de começar a construir.
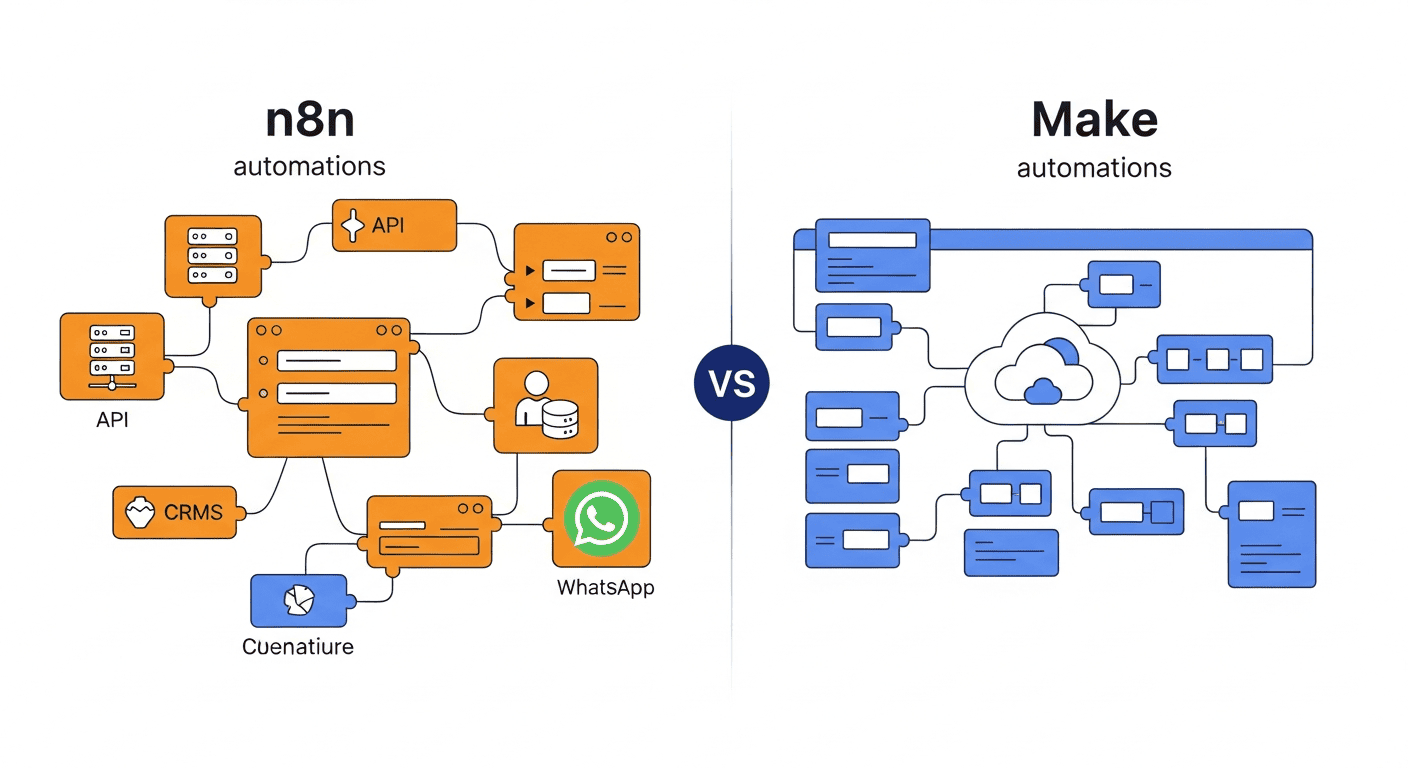
Em novembro de 2024, a Letta publicou um diagrama do stack de agentes de IA que virou referência padrão para boa parte dos times de engenharia. Se você já viu aquela imagem de camadas de um agente no LinkedIn ou fixada em algum canal do Slack, ela provavelmente veio dali. O problema é que esse diagrama já tem 14 meses, e muita coisa mudou desde então 🗺️
O MCP ainda não existia. Memória era tratada como um subconjunto do banco vetorial. Ninguém estava lançando SDKs nativos de agentes dos provedores. E avaliação nem entrava no mapa. Em 2026, o stack tem seis camadas, sendo que pelo menos três delas não existiam como categorias distintas quando o diagrama original foi desenhado. O artigo original que mapeia esse novo cenário foi publicado por Paolo Perrone no Substack The AI Engineer e republicado pela O’Reilly com permissão do autor.
Antes do Stack, Existe o Loop
Antes de falar sobre camadas e ferramentas, vale entender o que é um AI Agent de verdade. Um agente é definido pelo ciclo pensar-agir-observar: o modelo raciocina sobre uma tarefa, toma uma ação como chamar uma ferramenta ou gravar na memória, observa o resultado e repete o processo até a tarefa estar concluída. Esse loop é a unidade atômica. Todo o stack existe para fazer esse loop funcionar de forma confiável, em escala, em produção.
E aqui vai uma distinção fundamental: o stack de agentes não é o stack de LLM. Um chatbot precisa de inferência e talvez RAG. Um agente precisa de gerenciamento de estado em execuções com múltiplos passos, acesso a ferramentas governado por protocolos, memória que persiste entre sessões, loops de raciocínio autônomos e guardrails que restringem o comportamento em tempo real. São problemas de infraestrutura fundamentalmente diferentes.
Três coisas redesenharam o mapa entre 2024 e 2026. O MCP padronizou a conectividade de ferramentas, e a camada inteira de protocolos é nova por causa disso. Modelos de raciocínio como o1 e o3 mudaram o que agentes conseguem fazer de forma autônoma, com chamadas únicas substituindo algumas cadeias de múltiplos passos. E memória se tornou um primitivo arquitetural de primeira classe, não um adendo improvisado sobre um banco vetorial.
Como Avaliar Cada Camada do Stack
Na hora de escolher ferramentas em cada camada, três perguntas cortam a confusão:
- Quanta gestão de estado você precisa? Um chamador de ferramentas sem estado e um agente multi-sessão que aprende ao longo do tempo são problemas de engenharia completamente diferentes. As camadas onde o gerenciamento de estado é mais difícil, como memória e frameworks, são onde a maioria dos times empaca.
- Quanto vendor lock-in você tolera? MCP é um padrão aberto, SDKs de provedores não são. Cada escolha de ferramenta aumenta ou diminui a dor da sua próxima migração.
- Qual a distância entre demo e produção? Algumas camadas, como model serving, quase não têm gap. Outras, como eval e guardrails, têm um abismo. A camada onde você sente mais essa distância é a que merece investimento primeiro.
Camada 1: Modelos e Inferência
A primeira camada do stack é como você roda o modelo que alimenta seu agente: chamando uma API, usando um provedor gerenciado de modelos open weight ou fazendo self-host.
A camada de inferência mudou mais em tom do que em substância. Modelos de raciocínio como o1, o3, DeepSeek R1 e Claude com extended thinking mudaram o que agentes conseguem planejar e executar. Agentes que antes precisavam de cadeias com múltiplos passos agora resolvem problemas em uma única chamada de raciocínio. Modelos open weight como Llama 3.3, DeepSeek V3 e Qwen 2.5 fecharam o gap de qualidade de forma dramática, então o conselho antigo de sempre usar o maior modelo fechado já não é mais padrão. O padrão que está surgindo é prototipar em closed source e fazer deploy em open weight.
Na prática, essa camada está se comoditizando. As diferenças entre modelos importam menos a cada trimestre. A decisão real é o trade-off entre custo e latência, não qual modelo é o mais inteligente. Chamadas de API são stateless: manda um request, recebe uma resposta, sem nada para gerenciar. O risco de lock-in é alto para APIs fechadas porque cada modelo raciocina de forma diferente, e trocar de provedor significa reajustar prompts, adaptar para modos de falha diferentes e retestar toda a sua suíte de avaliação. Para open weight, o risco é baixo. O gap entre protótipo e produção é o menor de todas as camadas.
Considere self-host quando o volume de chamadas do seu agente tornar o pricing de API insustentável ou quando você precisa de latência abaixo de 100ms que round-trips de API não conseguem entregar.
Camada 2: Protocolos e Ferramentas
Essa camada trata de como seu agente chama ferramentas externas e APIs: através de servidores MCP, automação de browser ou protocolos agente-para-agente.

Essa camada não existia como categoria distinta em 2024. Cada framework tinha seu próprio schema JSON para definições de ferramentas. Agora o MCP é o padrão, com 97 milhões de downloads mensais do SDK, adoção pela OpenAI, Google e Microsoft, e doação para a Linux Foundation. O debate sobre protocolos acabou. O MCP venceu 🏆
O Browser Use explodiu em paralelo, atingindo 78 mil estrelas no GitHub em menos de um ano. Ninguém estava rodando agentes de browser em produção em 2024. E agentes agora podem conversar com outros agentes: a IBM lançou o ACP e o Google lançou o A2A. Nenhum dos dois é padrão ainda, mas o problema que eles resolvem, agentes coordenando com outros agentes, é real e crescente.
Segurança é o problema aberto. A Endor Labs analisou 2.614 servidores MCP e descobriu que 82% eram vulneráveis a path traversal e 67% a injeção de código. A única questão que resta é como você protege seus servidores MCP antes que alguém os explore. A OWASP publicou o MCP Top 10 em versão beta, que é o primeiro checklist real de segurança para agentes conectados a ferramentas.
O gerenciamento de estado aqui é inexistente: seu agente chama uma ferramenta, recebe uma resposta, pronto. O risco de lock-in é baixo porque MCP é padrão aberto. O gap entre demo e produção é médio: seu servidor MCP de demonstração funciona até alguém enviar uma descrição de ferramenta maliciosa.
Camada 3: Memória e Conhecimento — Muito Além do Banco Vetorial
A ideia de que memória em AI Agents se resume a embeddings e busca por similaridade ficou para trás. Em 2024, memória significava escolher um banco vetorial e fazer RAG. Em 2026, memória é um primitivo arquitetural de primeira classe com três níveis distintos, e todos alimentam o mesmo lugar: a janela de contexto que seu agente vê em cada chamada.
As janelas de contexto ficaram enormes. O Gemini chegou a mais de 1 milhão de tokens, o Claude a 200 mil. Mas janelas maiores não eliminaram a necessidade de memória. Elas mudaram o trade-off: o que você coloca direto no contexto versus o que você busca sob demanda?
Context Engineering Substituiu Prompt Engineering
Em vez de escrever um prompt melhor, a disciplina central agora é arquitetar qual informação o agente vê em cada chamada. Blocos de memória surgiram como campos nomeados e estruturados na janela de contexto que o agente pode ler e sobrescrever a cada turno. Em vez de jogar tudo no system prompt, o agente gerencia seu próprio estado: o que manter, o que atualizar, o que descartar.
Os Três Níveis de Memória
A memória de curto prazo, ou in-context memory, é o que vive dentro da janela de contexto durante uma única execução. É a mais rápida, a mais cara em tokens e a mais volátil. Quando a conversa termina, ela some. Para agentes que precisam apenas completar uma tarefa dentro de uma única sessão, isso basta. Mas quando o agente precisa retomar uma conversa dias depois ou lembrar preferências do usuário, a memória in-context sozinha não resolve.
Na infraestrutura, o pgvector se tornou o padrão para times que não precisam de um banco vetorial dedicado. É apenas Postgres com uma extensão. O GraphRAG emergiu como uma segunda opção de retrieval: seguir relacionamentos entre entidades em vez de combinar embeddings, com o Neo4j liderando esse espaço.
A memória de longo prazo é onde as coisas ficam interessantes. Ferramentas como Letta, Mem0 e Zep começaram a tratar memória persistente como cidadão de primeira classe, com operações de leitura e escrita explícitas, políticas de atualização e mecanismos de consolidação. O agente não apenas recupera informação, ele decide o que vale guardar, quando atualizar uma memória existente e quando descartar algo obsoleto. Essa capacidade de gestão ativa é o que diferencia um agente que parece inteligente de um que parece apenas reativo.
A maioria dos times complica demais a memória. Comece com histórico de conversa no Postgres e um system prompt estruturado. Adicione busca vetorial quando o histórico ultrapassar os limites de contexto. Adicione gerenciamento de memória agentic apenas quando seu agente precisar aprender entre sessões. O gap entre protótipo e produção é grande: memória de demo funciona porque as janelas de contexto são grandes o bastante, mas memória em produção quebra quando conversas ficam longas e o agente começa a esquecer as partes importantes.
Camada 4: Frameworks e SDKs — Escolhendo Sem se Perder
O ecossistema de frameworks para AI Agents explodiu. Todo grande lab de IA agora tem seu próprio SDK de agentes. A OpenAI tem o Agents SDK, que evoluiu do Swarm. O Google lançou o ADK. A Microsoft tem o Semantic Kernel e o AutoGen. A Hugging Face construiu o smolagents. Dois anos atrás, o LangChain era a única opção. Agora você escolhe entre três campos:
- SDKs de provedores: rápidos para começar, mas presos a um modelo
- Frameworks baseados em grafos como LangGraph: portáveis, mas exigem mais setup
- Sem framework: wrappers finos sobre APIs de provedores + MCP
Essa escolha simplesmente não existia em 2024.
O LangGraph se consolidou como líder de orquestração baseada em grafos com a versão 1.0 lançada em outubro de 2025 e deploys em produção na Uber, JPMorgan, LinkedIn e Klarna. Enquanto isso, o campo do faça você mesmo cresceu. Times que tentaram LangChain em 2024 e brigaram com a abstração agora estão escrevendo wrappers finos sobre APIs de provedores + MCP. Sem framework significa controle total, e isso funciona até seu agente precisar de gerenciamento de estado ou branching complexo.
Um ponto importante sobre nomenclatura: LangChain e LangGraph não são a mesma coisa. O LangChain é a camada de integração que cuida de conectores de modelo, tool calling e templates de prompt. O LangGraph é o motor de orquestração que gerencia estado, fluxo de controle e grafos. A maioria dos times em produção usa os dois juntos, mas o LangGraph é onde a lógica do agente vive.
O risco de lock-in nessa camada é o mais alto do stack inteiro. Seu código de orquestração não é portável. Um agente LangGraph reescrito para CrewAI é um codebase novo. SDKs de provedores são piores porque você fica preso a um modelo também. A maioria dos times escolhe framework demais. Se seu agente chama um modelo e algumas ferramentas, você não precisa do LangGraph. Um SDK de provedor e algumas chamadas de ferramenta vão te levar à produção mais rápido do que qualquer grafo.
Camada 5: Avaliação e Observabilidade — A Camada Que Ninguém Colocava no Mapa
Se tem uma coisa que o diagrama original não cobria e que hoje é tratada como crítica, é avaliação. Essa camada praticamente não existia em 2024. Agora ela é o gap. A pesquisa State of Agent Engineering do LangChain descobriu que 89% dos times com agentes em produção implementaram observabilidade, mas apenas 52% têm evals. Esse gap de 37 pontos é onde a qualidade de produção morre 📊
Avaliar um AI Agent é fundamentalmente diferente de avaliar um LLM isolado. Quando você testa um modelo, passa um prompt, recebe uma resposta e compara com uma referência. Quando você avalia um agente, está lidando com sequências de decisões, chamadas a ferramentas externas, estados intermediários, memória que evolui ao longo do tempo e resultados que às vezes só fazem sentido no contexto de toda a trajetória do agente.
Três Dimensões de Avaliação
A abordagem que está convergindo separa pelo menos três níveis:
- Checks rápidos em cada PR: o agente chamou as ferramentas certas?
- Suítes de regressão noturnas: usam um LLM para julgar a qualidade do output
- Monitoramento contínuo em produção: alerta quando a performance do agente começa a degradar
Novos benchmarks específicos para agentes também surgiram, incluindo o Context-Bench para gestão de memória, o Recovery-Bench para recuperação de erros e o Terminal-Bench para agentes de código.
Ferramentas como LangSmith, Braintrust e Arize estão evoluindo rapidamente para cobrir essas dimensões. Mas o ponto mais importante não é qual ferramenta você usa, é quando você começa a pensar nisso. Times que deixam avaliação para o final invariavelmente descobrem que precisam rearquitetar partes do sistema para que ele seja observável o suficiente para ser avaliado. A maioria dos protótipos tem zero eval. Você não sente a dor até que os usuários em produção encontrem as falhas por você.
Camada 6: Guardrails e Segurança
Guardrails de agentes se tornaram uma disciplina separada de guardrails de LLM. Em 2024, guardrails significava filtros de input/output em um modelo. Em 2026, seu agente chama ferramentas, gasta dinheiro e toma ações. Guardrails agora significa autorizar chamadas de ferramentas, impor rate limits e validar o que o agente realmente fez.
O padrão de guardrails antes da ação surgiu de times que aprenderam da pior forma. Eles agora aplicam autorização na camada de execução de ferramentas, não na camada de output. Porque quando você filtra a resposta, o agente já mandou o email.
Essa é a camada menos madura do stack inteiro. Não existe framework dominante nem padrões estabelecidos. Você está escrevendo código de política do zero. O NeMo Guardrails é o mais próximo de um framework, mas você ainda vai escrever a maioria das regras manualmente. O gap entre demo e produção é efetivamente infinito: sua demo não tem guardrails porque ninguém está tentando quebrá-la. Produção vai ter.
E se você está rodando workflows multi-agente onde agentes delegam uns para os outros, a propagação de guardrails através das fronteiras entre agentes é um problema em aberto. Vai precisar de lógica de autorização customizada.
Qual Tipo de Agente Você Está Construindo?
Essa é a decisão que corta toda a confusão sobre frameworks. O tipo de agente determina em quais camadas você investe e quais ferramentas escolher em cada uma.
Chamador de Ferramentas Stateless
Responde perguntas de uma base de conhecimento, consulta um pedido ou verifica estoque. Você precisa de um SDK de provedor, MCP e Postgres. Sem framework, sem banco vetorial. Isso é um projeto de fim de semana.
Workflow com Múltiplos Passos
Processa um reembolso de ponta a ponta, revisa um PR em cinco arquivos ou faz triagem e roteamento de tickets de suporte. Os passos dependem uns dos outros, coisas falham no meio e humanos precisam aprovar antes do agente agir. Você precisa de LangGraph, MCP e eval. Construa evals antes de fazer deploy porque esses agentes quebram silenciosamente.
Agente Que Aprende
Lembra suas preferências entre sessões, melhora no seu codebase ao longo do tempo ou rastreia contexto de projeto por semanas. Você precisa de uma arquitetura memory-first, banco vetorial e eval. A orquestração é a parte fácil. A parte difícil é decidir o que lembrar, o que descartar e como impedir que contexto antigo polua respostas novas.
Sistema Multi-Agente
Agentes que delegam para outros agentes, dividem uma tarefa de pesquisa entre especialistas ou rodam workstreams paralelos. Você precisa do stack completo. Dois agentes passando contexto um para o outro já é difícil de debugar. Cinco é impossível sem evals no nível de trace em cada handoff. Construa infraestrutura de eval antes de construir o segundo agente.
Agentes de Código: As 6 Camadas em Ação
Agentes de código como Cursor, Claude Code, Codex e Windsurf são a aplicação mais comprovada do stack de AI Agents. Todas as seis camadas trabalhando juntas.
Na camada de inferência, essas ferramentas servem centenas de milhões de requisições diárias. O Cursor roteia entre Claude, GPT-4 e seus próprios modelos fine-tuned dependendo da tarefa. Na camada de protocolos, servidores MCP conectam a editores, terminais, sistemas de arquivos e Git, que é como o agente lê seu código e roda comandos. Na camada de memória, retrieval com awareness do codebase e reranking garante que o agente não leia seu repo inteiro, apenas os arquivos relevantes para aquela edição específica.
Na camada de frameworks, esses são sistemas de orquestração customizados com loops de RL. Não é LangGraph, não é SDK de provedor. Fluxo de controle construído sob medida para geração, revisão e iteração de código. Na camada de eval, o Cursor retreina seu modelo de taxa de aceitação a cada 90 minutos com base em se os usuários aceitam ou rejeitam as sugestões. Isso é eval rodando em produção, continuamente. E na camada de guardrails, execução em sandbox previne agentes descontrolados. O agente pode escrever e rodar código, mas dentro de um container que limita o que ele pode tocar.
O Panorama Geral: Pare de Construir Como se Fosse 2024
A maioria dos times está construindo como se ainda fosse 2024. Escolhem LangGraph antes de saber se precisam de estado. Adicionam banco vetorial antes de terem superado o Postgres. Desenham arquiteturas multi-agente antes de terem enviado um único agente que funciona.
Um chatbot que chama ferramentas e um sistema de pesquisa multi-agente praticamente não compartilham infraestrutura. Tratar os dois da mesma forma significa overbuildar o primeiro e underbuildar o segundo.
Os times que passaram desse ponto rodam evals em cada deploy, não uma vez por trimestre. Seus guardrails ficam na camada de chamada de ferramenta, não na camada de output. Sua arquitetura de memória foi projetada intencionalmente, não herdada do default do framework. A maioria dos times faz o oposto: zero evals, filtragem apenas no output e um system prompt que cresce até a janela de contexto engasgar.
O gap não é talento ou orçamento. É saber quais camadas importam para o seu agente específico em vez de meio-construir todas as seis.
O stack de AI Agents em 2026 é mais maduro, mais fragmentado e mais exigente do que era 14 meses atrás. Cada camada tem suas próprias decisões de design, suas próprias ferramentas em competição e seus próprios trade-offs que só ficam visíveis quando você está construindo algo real. E uma tendência clara está no horizonte: SDKs de provedores já estão absorvendo memória, tool calling e eval básico em uma única API. Até o início de 2027, a maioria dos times provavelmente não vai construir cada camada separadamente. Vai receber um stack cada vez mais opinado do seu provedor de modelo, e isso vai funcionar para 80% dos casos. Os outros 20%, agentes em escala onde os defaults quebram, ainda vão construir customizado em cada camada. Mas mesmo nesses casos, quando algo falha em produção, você precisa saber qual camada falhou. Mapear essas camadas antes de escolher qualquer ferramenta não é burocracia de engenharia, é o que separa sistemas que funcionam em produção de sistemas que funcionam apenas na demo.